
与AI同行:面对AI烈火
重要观点
从个人感受、技术认知到行动建议,系统拆解普通人、创业者与投资者如何面对 AI 这场烈火。
1 前言
一些感受,一些现象,一些观点,一些吐槽
为什么AI会裹挟大家,使得我们不得不应对?
AI不同于一个研报,是一场席卷人类的趋势,是比工业革命更深入的智能革命,以前的钢材革命,蒸汽机革命,都是特定的,我是工厂主我受影响,我是相关企业,即过去有得选,你可以说这个趋势我不关注也没什么损失,但AI或者智能革命好像不是这样,它好像真的会切实地改变很多东西,它好像真的是跟我息息相关的,哪怕我不情愿。它是E人革命,它不是I人革命,I人革命是这样的,敲门,我可以进来吗,不可以的话,我就不打扰了,而是直接把门踹开,小夫我要进来了咯,然后进来坐在你沙发上开始自己倒水喝了。
今天的分享可能部份地方会比较尖锐,如果有被刺到不要迁就到我头上,我也是信息和观点的搬运工,报告多数观点不代表本人100%认可。
AI问题
- AI本质是什么?
- AI目前在什么阶段?
- AI行业目前面临的问题是什么?
- AI的终局是什么?
- 从现在到终局还差什么?
- AI能帮助我们做什么,AI能解决什么问题
- AI能带来什么样的范式转移
- AI又什么方向是明确的,值得投资的
- AI趋势意味着什么
- AI趋势下,作为个体的我该如何应对
- AI趋势下,什么企业在融资,解决什么问题
- 不想只是着眼于一些观点,而是希望有一套可供大家参考的理解框架
- 收集他山之石/史,希望可以攻玉
2 感受:AI的杰文斯悖论
老实话,这段时间我的感受五味杂陈,AI的出现并没有使得我更轻松。
为什么?很多人包括我在内,对AI的第一反应,是它会让工作变得更轻松,尤其是我在使用和探索AI上是很大胆的维新派,给人感觉AI应该玩得很溜,现实是恰恰相反的,朋友有一天无心吐槽我说:“AI后的俊哥反而更忙”。那天真的把我问住了,我突然想我难道被AI奴隶了吗?还有就是前几天邱总说你可以两周分享一次,虽然我没有照镜子,但我回想起来我当时应该是一个苦瓜脸。
为什么呢?为什么AI出现后很多人效率提高了,反而更忙了?
因为AI让交差变得简单,却让本分变得更难了,以前难,是因为很多事情你做不到,现在更难,是因为太多事情你都做得到。AI一方面减负重复性工作,另一方面却让每个人能力边界被猛地抬高,能做的事情一下子变得太多了。过去很多想法,因为执行成本太高,你需要能力,你需要同事沟通,你需要协调各种东西,想想也就算了;现在不同,很多原本做不到、懒得做、来不及做的事情,突然都变成了可行选项。
拿我自己举例,对于文字工作者而言,客观上来说文本的生成变成了极其简单,一篇有模有样的研报生成是非常轻松的,几乎没有门槛的,加上一些提示词,大多数人看不出什么问题。如果我只想应付,确实是越来越轻松,但为什么不呢,是我不想吗,~~不是的,~~而是我不可逃避地认识到如果我聚集大家的时间,铺垫了很久,盛大开场,全体人员向我看齐,然后把端上桌一道AI的预制菜,哪怕预制菜已经达到比较高的水准,但我会有一种我在背刺大家的不配得感,我会觉得难受/不舒服,在面对这份本职工作,在面对大家的时候,我可能是想要对得起一份信任,或者守住自己的本分。
这是我个人对AI时代杰文斯悖论的感受,很反直觉的观点,AI(硅基智能)并没有消灭工作,它只是先把工作里机械、表层、容易糊弄的那部分卷走了。留下来的,恰恰是更难被替代、也更不能逃避的部分,暂时属于人(碳基智能)的部份,比如品味/审美(taste),诚实/真实,历史,目标,责任,取舍,社交,纽带,体验,判断,认知,思维,动力……
杰文斯悖论:技术进步提高了资源使用效率,但因成本下降刺激需求暴增,最终导致资源总消耗量不减反增的现象。瓦特改进蒸汽机使煤炭利用效率大幅提高,本意是减少能耗,但更高效的蒸汽机使得使用成本降低,反而使得更多场景和需求使用蒸汽机,最终导致能耗增加。
聊这么多不是我想上价值,或者借机夸自己,而是面对AI这么一个大的,时代的,无孔不入的课题,怎么切入都感觉不得劲,不如从自己的真实感受出发,告诉大家AI正在解构和重构很多旧认知和旧定义,同时它也像镜子版,强势地使每个人重新审视很多东西,你和AI的关系,你和自己的关系,你和工作的关系,你和他人的关系……,我相信大家可能在某个时刻会被打到——用AI越多反而会倒逼你面对自己,你到底要什么,你到底是怎么想的。
AI替代不了我们面对自己,AI在逼迫我们面对自己。

3 丙午年:AI这场大火
面对这样的突如其来的处境,很多人会下意识不知所措,这种处境很像高考结束,选专业为什么难?高中很多人只要会应试拿高分,高考完突然告诉你,你几天内要选好专业,从无限的可能性里选好你一辈子从事的行业,你自己选的还要自己为自己负责。
AI尤其今年1月OPENCLAW就是这么一场大考,像流星一般炸到人类世界后,就感觉丙午年的大火实质化了,就很真实的被炙烤的感觉,这大火是对所有人的一次突击高考,不是拷打你如何使用工具,而是当硅基智能真的可以和碳基生物一起肩并肩,上桌吃饭了,可以替你写东西,替你做部份工作,这部分过去既保护你又限制你的东西被燃烧殆尽后,燃烧的灰烬是营养(多出来的时间精力),但它更护的花是什么?剩下的真金是什么呢?
所以为什么今年,尤其是Openclaw和其他AI产品出现后,焦虑/迷茫/兴奋的在加速出现?
因为它们确实在以焚毁的方式摧毁了人类给自己预设的思维限制,将我们暴露在一个广阔无垠的世界里。
1954年,Roger Bannister 以3分59秒跑完 1 英里,打破的不只是一个纪录,更是一个持续近百年的集体心理魔咒。那之前,人们以为限制人类的是心肺,是肌肉,是身体这个架构的物理边界,但RB说:“关键器官是大脑,而不是心脏或肺”。正是因为如此,他破纪录后的鸡汤才格外有分量——“无论我们每个人看起来多么平凡,但在某种程度上,我们都是特别的,并且可以做非凡的事情。也许在那之前,甚至被认为是不可能的”

更有意思的是,这个极限一旦被打破,不可能就迅速从神话变成了日常:
- 澳大利亚运动员John Landy刷新了记录3分57秒
- 1955年,超过37名运动员都在4分钟内跑完了1英里。
- 1956年,超过300名运动员突破了4分钟极限。
- 如今最好成绩已经刷新到1999年的3分43秒。
Openclaw和其他震撼的AI产品,可能就是当下的Roger Bannister时刻,Openclaw并没有什么特别大的创新,很多人也说它的单个功能很多产品早就能做到了,它未必是凭空创造了什么前所未有的物理能力,而是第一次把很多人原本只敢停留在想象、演示和科幻里的东西,觉得不可能的事情硬生生拉进了现实,使得人可以体验,可以亲眼所见,进而拆掉思维的墙。
延伸阅读:《积极心理学》:思维的限制
延申案例:张雪的有梦就去追系列
4 理性:如何应对?
这么大的课题,不管是AI抛过来,还是我抛给大家,没有答案应该是常态,分享的目的是如果AI这场大火注定要越来越强,越来越多地进入我们的工作与生活,那人与自己的关系,人与工具的关系,人与自己的关系,迟早要被拉出来全部重新审视,甚至重新组织,既然迟早要被拷打的,不如主动拷打自己,看看在这样的大风、大浪、大火里,到底什么会变,什么不会变,什么值得抓,什么必须放。
面对AI的热浪,人类如何应对?
面对剧变,除了观望派,人类的应对思路大概是两个:
向前试错,跟上变化,摸着石头过河;
向后扎根,找到不变,顺着历史找锚。
4.1 往前:把裤脚搞脏
向前试错,不是追热点,不是每天收藏几十个工具,不是看完几个大 V 的总结就以为自己理解了时代。真正的向前试错,是把 AI 拉进真实问题里。把它拉进你的工作流,拉进你的任务拆解,拉进你的思考过程,拉进你的表达与协作里。让它不只是一个聊天窗口,而是一个会真正影响你做事方式的变量。
向前试错还有一个容易被忽略的意义,就是人类不可或缺的体验,体验会带来知行合一,进而带来驱动力。你不用 AI,只靠旁观,你也许能说出很多漂亮判断,但那种判断没有体验支撑很容易抛之脑后,建议纸上得来终觉浅,绝知此事要躬行。
把裤脚搞脏,亲自下水,亲手用,亲自把工作流拆了重组,亲自感受硅基智能的边界、幻觉、效率,愚蠢与聪明,只有当 AI 真的进入你的工作和生活,你才会知道什么叫能力边界被拔高,什么叫选择过多导致的不知所措,什么叫一个人被突然推进无限可能性之后的焦虑/兴奋,什么叫卧槽AI把东西做出来后的这都行的惊讶。
4.2 往后:向历史学习
但只一昧追求热点也会出问题。因为热点变化太快了,你今天追模型,明天追工作流,后天追Agent,过几天又来一个OpenClaw,再来一个协议、一个新入口、一个新玩法,很容易变成一个被时代拖着跑的人,表面上天天在前线,实际上精神内核越来越空。忙,兴奋,焦虑,什么都懂一点,最后什么都抓不住。
向后扎根的思路就是向历史里找答案,不是逃避变化,不是“向来如此,便对么”,而是经得起历史选择,经得起时间不丢失,经得起一代代人选择,沉淀下来的不变的东西,更容易扛得住AI这场智能革命的大变化。
一个有趣的观察或许有启发意义,其实AI的出现和原子弹爆炸一样,成为了时代的背景板,是所有人无法躲避的背景音。
- 1945年,奥本海默引爆第一个原子弹后,物理环境遭染,放射性同位素弥漫全球,开放环境下炼钢会使得钢材带上放射性同位素,虽对人类无害但会出现微弱噪音,早期的医院精密仪器为了防止噪音需要用沉船里的钢材。
- 2022年,GPT诞生后,信息环境遭染,大模型的逻辑特征使得新信息被动带上了AI的指纹,互联网的新生信息,文本/音频/视频都不可避免会有AI的味道。
- 2026年,OPENCLAW诞生后,执行环境遭染,一句话不再是文本,还可能是行动本身,接入越来越多权限系统,触及越来越多生产环境的智能体,使得魔法世界里的言出法随正在部份成为现实。
从原子弹的例子来看,历史里沉淀着那些先于 AI 而存在的东西。一个认知、一种原则、一套智慧,能够穿越几百年、上千年,被一代又一代人反复传承、反复验证,本身就说明它触碰到的是人类经验中更深的部分。技术会变,工具会变,界面会变,但有些东西变得很慢,比如人性、欲望、判断、责任、关系、秩序、意义感,以及人在不确定世界里如何安顿自己。向历史学习,本质上不是复古,而是在剧变中重新找到那些被时间筛过、被人类长期认可、真正属于人的、不那么容易被时代噪音冲刷掉的东西。
延伸阅读:我用1400年前的三省六部制,搞了一套很酷的多Agent协同方案
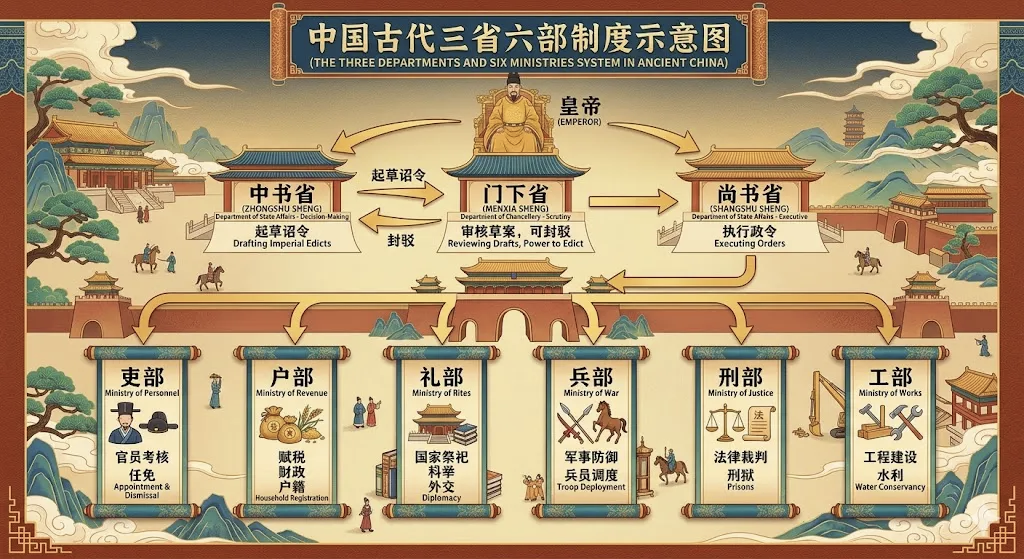
5 学习:谁是什么?
火来了,火很大,然后呢?怎么办?
在进入落地章节前需要叠甲,不是因为我已经有了什么标准答案,恰恰相反,是因为当下可能根本不存在标准答案。
所有人都还在摸着石头过河,没有谁的经验是恒久有效的,也没有谁的方向是保证正确的。AI 变化得太快,模型在变,产品在变,接口在变,工作流在变,人与它的关系也在变。今天看起来很顺手的方法,明天未必还成立,今天看起来很笃定的判断,明天也可能被现实打脸。网上有句玩笑话是说AI时代,学得太晚就不用学了,这句话的道理在于我们这次面临的变化是智能体变革,是双向的交互,所以有些问题对方可以学习,可以解决,但有些问题是不属于这个范畴,人类方还是要努努力。
这个章节的内容,如果是主观观点,不代表我认可,更没有对错,我可能也是复述,更希望是借着一些东西能让大家思考,或者一起讨论。某种意义上,这反而是考验人类多样性的时刻,不是所有人都要用同一种姿势摸河,也不是所有人都要在同一个火堆旁边烤同一种串。恰恰因为没有统一答案,足够多的人带着不同经验、不同判断、不同偏好去试,新的路径和新的可能才更容易涌现出来。
不要害怕你的姿势不够标准。相反,那些奇奇怪怪的用法,那些带有个人偏见、独特品味甚至是一点点偏执的尝试,才是最珍贵的资产。因为在算法最容易模拟的标准化路径之外,这些由人类多样性碰撞出来的灵感火花,才是可能产生下一次班尼斯特时刻的种子。
这个学习不可跳过,我会尽可能地避开术语,理解了很多概念是什么意思,解决什么问题,才能更好地理解后面的章节,个人如何使用AI和创业者在鼓捣什么。
5.1 硅基智能如何思考?
大的背景信息
需求:让机器理解语言,处理自然语言
旧方案:思路模仿人类,RNN、LSTM、GRU 类循环神经网络
问题:串行的架构太慢了,句子长了会遗忘
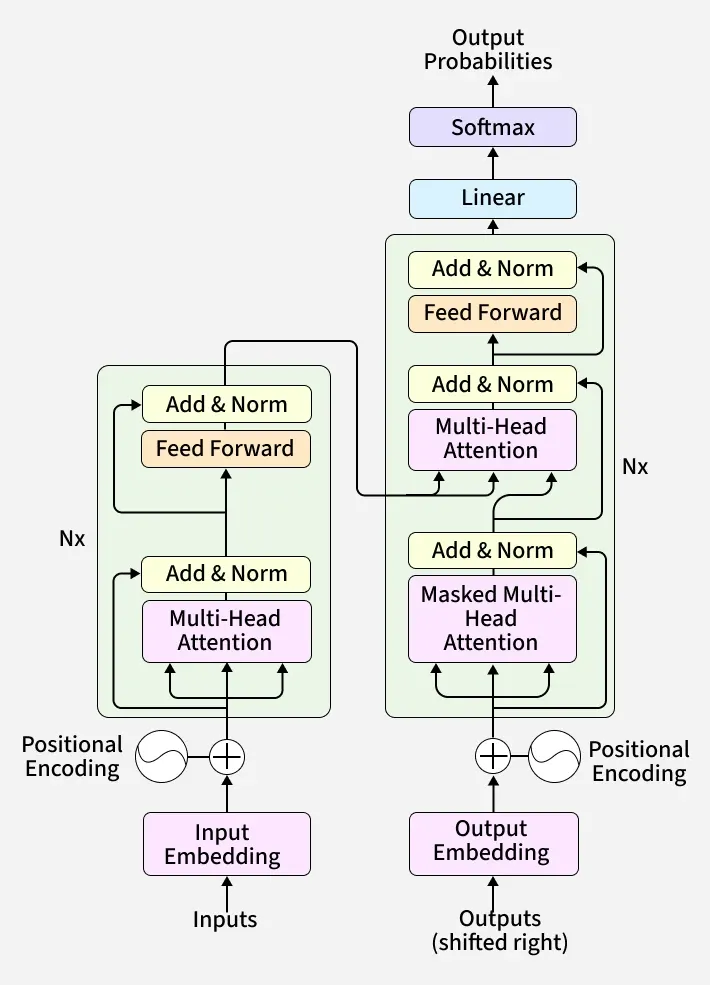
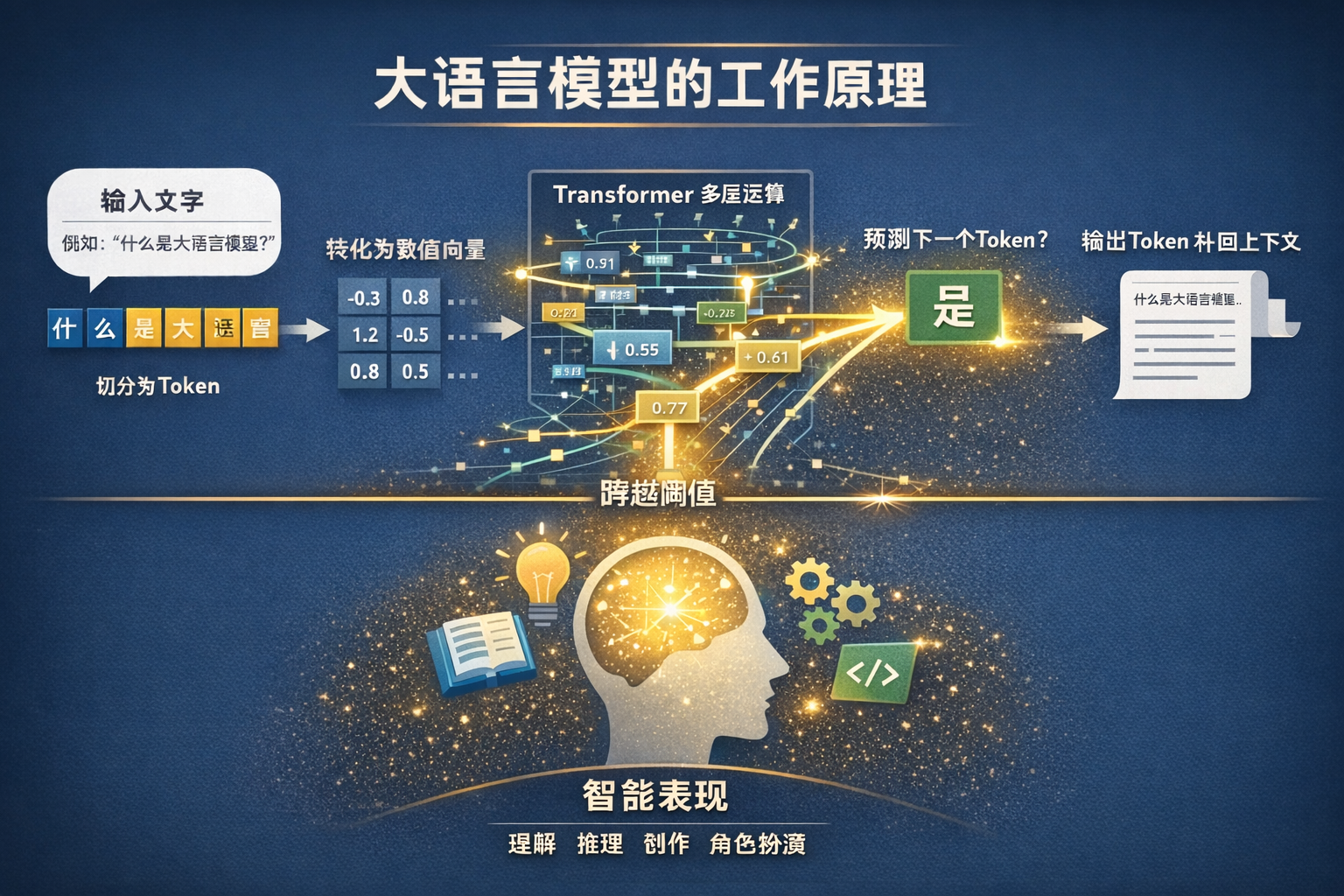
《Attention is All You Need》是指2017年由谷歌团队发表的一篇具有里程碑意义的深度学习论文,该论文提出了Transformer神经网络架构,起初Goole是想解决机器翻译的问题,但结果是改变了自然语言处理等领域的模型设计范式,是AI的共同亲生父亲。
Q1:什么是 Transformer 架构?
Transformer 是一种专门为处理序列信息而设计的神经网络架构。Transformer 的突破在于,它不再把让机器理解语言的路径建立在对人类的模仿上,而是改成让每个词都能直接和全局发生关系。这篇论文的意义在于,它通过三个概念组合跳出了以往的范式来解决模型理解语言的问题,使得模型处理处理词与词有了三个跃进,万物向量化+输入保留次序+无视距离关联+全局并行处理。
细节
Transformer本质是一个目标函数,最小化预测下一个字符的损失函数。,在海量数据中寻找点与点之间的关联度。从这个角度看,基于Transformer架构的智能体像是一个外星人,手里拿着无限被塞入的人类数据,通过查询来回答问题。
AI是否有逻辑?
字符的寻找是基于对人类知识库高纬度压缩后的隐性逻辑重构,他是万物向量化后的逆向工程后的再输出。所以数字化模拟或者计算的逻辑和人类的体验是否可能是同一回事?
1 Self-Attention(自注意力机制)
解决词的关联问题,词与词不按顺序关联,而是无视顺序和距离按关系关联,每个词都同时看向其他所有的词。
数学表达:Attention(Q, K, V) = softmax((QK^T) / sqrt(d_k))V
每个词在处理自己的时候会用三个视角
- Query:我现在想找什么
- Key:我身上贴了什么标签方便别人来找
- Value:我携带的内容
2 Parallelization(并行化)
由于解放了顺序,模型便可以无限并行处理和计算,只要算力够。
3 Positional Encoding(位置编码)
因为全图扫描会导致模型分不清词的先后顺序(比如 我打你 和 你打我 看起来是一样的),科学家给每个词加了一个位置标签。
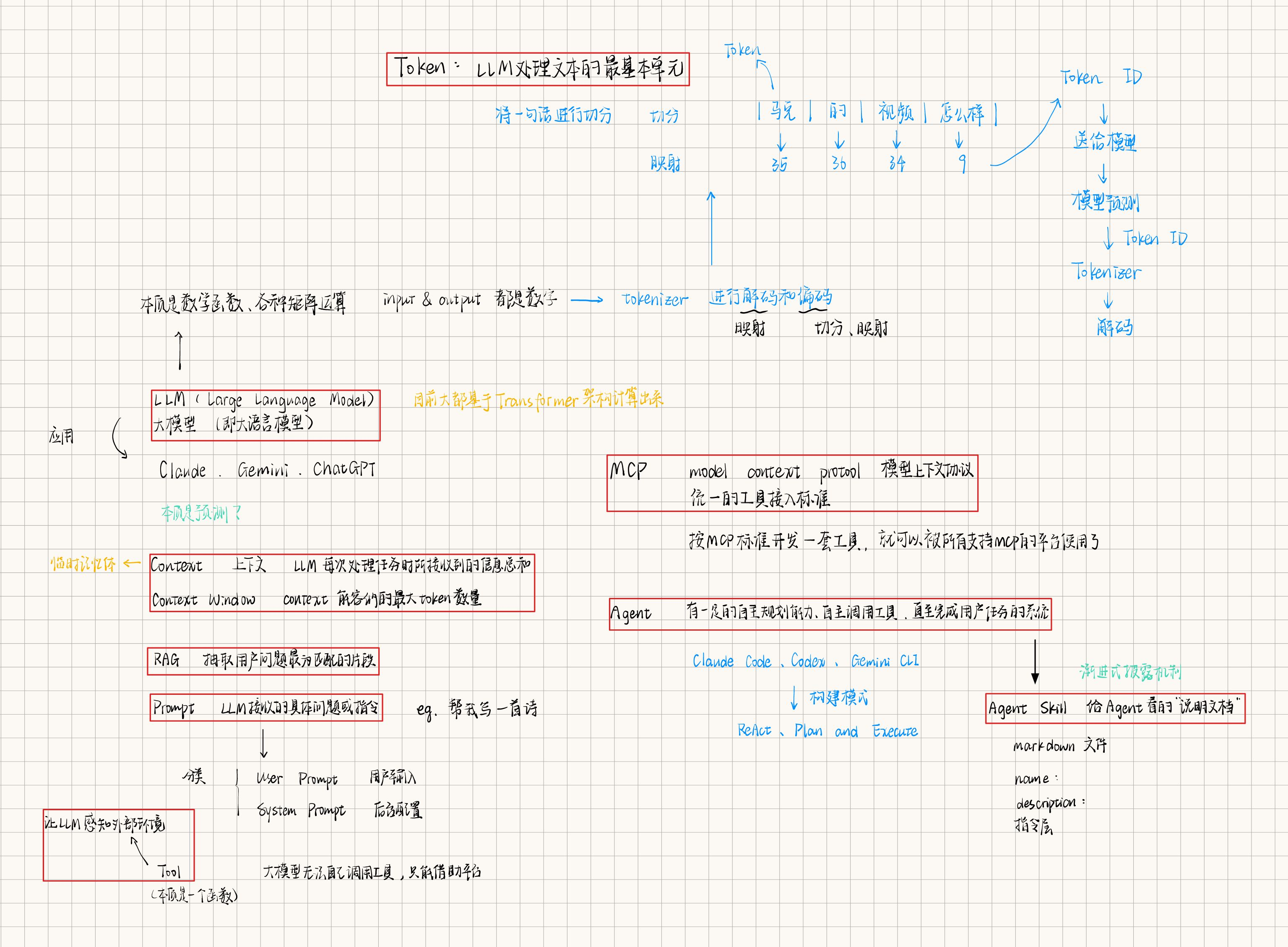
Q2:什么是大语言模型(LLM)?
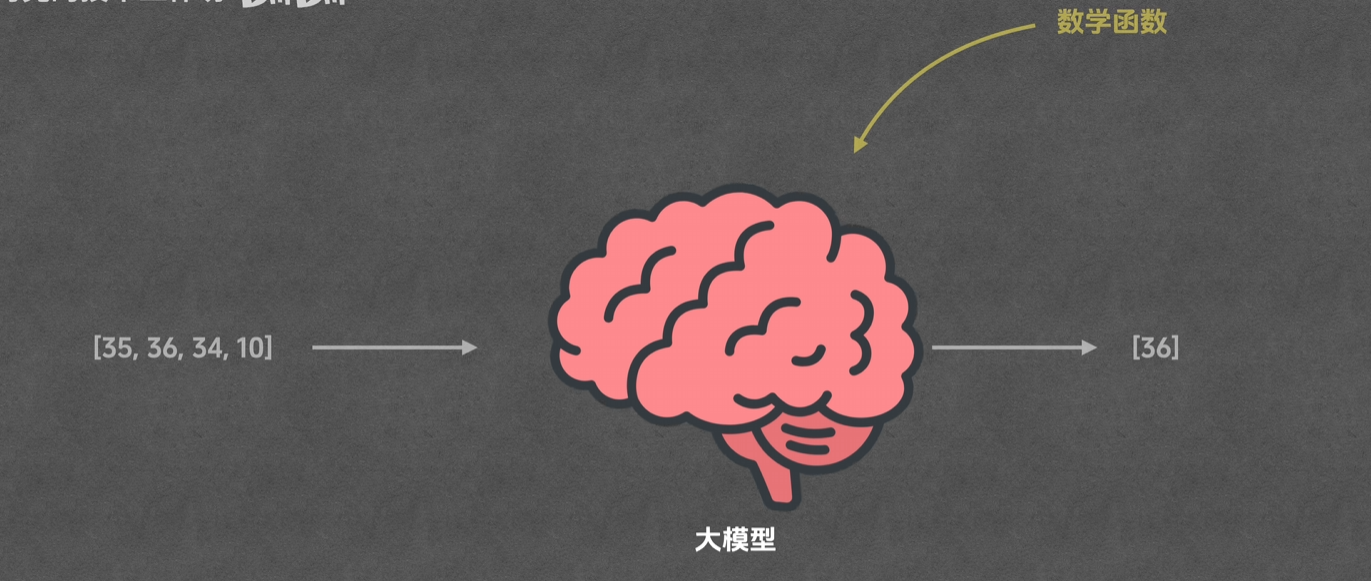
如果从第一性原理出发,大模型最底层并不神秘,它本质上是一个数学函数F(x) = y,更准确地说,它不是单一公式,而是由海量可训练参数和多层结构共同组成的复杂函数系统。大模型的底层世界里,没有诗意,没有语言,只有数字和运算。
从运行机制上说,大模型做的就是一件事情:根据已有序列,预测下一个 token。

Teamo生成
人类生成
它会先读取输入,把输入切成 Token,再经过多层矩阵运算,计算在「当前上下文下」下一个最可能出现的 Token 概率分布,然后选出一个 Token 输出。输出之后,这个新 Token 又会被补回上下文中,模型继续预测下一个 Token,如此循环,直到遇到结束标记,或者达到生成长度上限。也就是说,模型表面上是在写文章、答问题、写代码,底层其实一直在干同一件事:根据上下文预测下一个 Token。
大模型如何从数学函数演变成“智能”?
当这个函数足够大,参数足够多,训练数据足够丰富,结构设计足够合理时,它对下一个 token 的预测能力会跨过某个关键阈值。一旦跨过这个阈值,它输出的就不再只是机械的词语接龙,而开始表现出理解上下文、保持一致性、模仿推理、调用知识、生成代码、扮演角色等一系列能力。于是在人类看来,这个系统就表现出了某种智能。
gemini生成
GPT生成
Q3:什么是蒸馏?
蒸馏,英文叫 Distillation 或 Knowledge Distillation。它的核心思想是,让一个更强、更大、更贵的模型当老师,把它已经学会的能力、判断模式和输出规律,迁移给一个更小、更轻、更便宜的模型。
这样小模型虽然脑子没老师那么大,那么多参数,那么会算,但能学到老师一部分本事,跑得更快,成本更低。
蒸馏现在也有广义的用法,中国修仙小说似乎有个更合适的词,叫炼化


延伸阅读:女娲.skill:下一个同事何必是身边人
我不需要一个假的芒格。我需要的是,做判断的时候能快速切换到芒格的视角看一眼。
5.2 硅基智能如何沟通?
Token(词元)、Context(上下文)和Context Window(上下文窗口)。理解这三者,是掌握与AI高效沟通技巧的第一步,也是理解很多AI创业者发力的点是什么。
Q4:什么是 Token(词元)?
Token是LLM处理文本的最小单位
硅基智能的货币
哥,再给我点 Token 吧,我快不行了,求你了哥,我感觉我身上有蚂蚁在爬,我感觉我浑身都在抖,快不能呼吸了,求求你了哥,就再给我一点 token 吧,就一点就行,我再也不碰了,求求你了哥,真的,就一点 token,我发誓我以后再也不碰这东西了,我实在忍不下去了

Q5:什么是 Prompt?提示词
Promp是我们给模型的输入,是你向模型提供的任务描述、背景信息、约束条件和输出要求的总和。Prompt 的质量,会直接影响模型最后沿哪条概率路径生成答案。
User Prompt(用户提示):用户跟AI说的话,给AI的指令
System Prompt(系统提示):开发者预设在AI模型背后的一段角色设定或行为准则。它对用户是不可见的,但却在底层指导着AI的整体行为风格和能力边界。
*Claude 内部有一个 Coordinator(项目经理)模式
“永远不要写‘根据你的发现去修复这个 bug’。这种话是在把理解力外包给下属。你必须自己理解了研究结果,然后写清楚:改哪个文件、第几行、为什么改、改成什么”*
Claud的常驻后台,记忆蒸馏
“只记那些无法从代码和 Git 历史中推导出来的信息。代码模式、架构、文件结构——这些不用记,grep(搜索)一下就有了。你要记的是:人的偏好、人的决策、人的反馈。”
Prompt engeering 提示词工程:如何把话跟硅基智能体说明白,说清楚
- 虽然不用把话说明白,对方也能明白,但结构化/信息量丰富的Prompt还是有用的,能引导智能体给出精准/深刻/超预期的回答,可以网上抄作业。
- 目标如果是得到预期的回答,设定角色比提示词工程优先级高,设定角色底层原理是设定边界/约束范围/限制,是高度压缩的一组提示词,能屏蔽无关的内容分支,但过强的角色会压缩探索空间,需要跨界的答案。
现在有一种声音是说在任务划分场景里不要具体指示,提出 intent driven 理念,认为传统的 SDD 模式是误入歧途,应像老板告诉员工目标一样,直接告诉 AI 需求,让 AI 自行思考如何实现,避免像管理人类一样拆分任务。 arkblock ceo老冒
- 好的prompt具备的要素
- 角色(Role):你希望AI扮演什么角色?(如:资深程序员、营销专家)
- 背景(Context):提供必要的背景信息和上下文。
- 任务(Task):明确指出需要完成的具体任务。
- 格式(Format):指定输出的格式要求(如:表格、代码、JSON)。
- 示例(Examples):提供一个或多个示例,让AI更好地理解你的期望。
Q6:什么是 Context?上下文
从对话到会话,以前AI是一次对话,现在AI是多轮对话,诞生了Session会话的概念。
Context是我们在与LLM进行一次Session对话时,输入给它的所有信息的总和。这包括我们的提问(Prompt)、以及之前的所有对话历史、长期偏好、个性化。Context就是LLM在处理当前任务时的临时记忆。
Context Window是Context所能容纳的Token数量上限。如果对话超过了这个限制,LLM就会开始忘记最早期的信息,这被称为失忆现象。
人类的极限:心理学有个著名的“7±2效应”,普通人脑的短期工作记忆只能同时处理 5 到 9 个信息块。你的办公桌(大脑内存)只有半平米,看第 3 份文件时,第 1 份文件的细节就忘了。
百万Token的AI:它拥有一个足球场那么大的办公桌。100万 Token 相当于 75 万个英文单词,大概是 10到15本大部头名著,或者一个中大型软件的全部源代码。
什么是Context工程?
硅基智能与碳基智能有两条优化路线,1是优化碳基生物的表达,2是优化硅基智能的理解,更系统的被隐藏到后端,用户没有直接感知但其实在实际发挥作用的提示词工程,在正确的时机给大模型输入正确的信息。
上下文工程就是让给硅基智能搭建框架,优化一整套输入系统,而不是优化一次输入。
上下文工程:RAG检索增强,上下文压缩、任务状态
什么是skil?
渐进式披露,不是一上来就把所有工具说明参数都丢给大模型,而是合适的时机合适的调用。da
- 延伸概念
概念 人话解释 Context Engineering 不再只琢磨怎么写一句 prompt,而是系统性地决定这次到底该给模型看什么、按什么顺序看。 (anthropic.com) Context Assembler 上下文拼装器,把 system prompt、用户问题、历史、记忆、检索结果、工具输出拼成一次真正送入模型的输入。 Retrieval / RAG 当模型参数里没有现成答案时,先去外部找资料,再把相关内容塞回上下文。 Contextual Retrieval 不是只按关键词找材料,而是尽量结合上下文去找真正相关的材料,减少找错文档。 (anthropic.com) Reranking 检索回来一堆材料后,再排一次序,把最相关的放前面,别让垃圾信息先占坑。 Query Rewriting 先把用户原问题改写成更适合检索的问法,再去查资料。 Chunking 把长文切成合适的小块,太大难定位,太小又容易丢语义。 Session Memory 管理单次会话内的短期记忆,常见方法是裁剪和压缩,避免历史太长把窗口撑爆。 (OpenAI 开发者) Long-Term Memory 存用户偏好、长期目标、稳定事实,不是每轮全塞进去,而是按需取回。 (OpenAI 开发者) Memory Injection 把检索到的记忆或偏好,在当前这一轮按需注入上下文。 (OpenAI 开发者) Compression / Summarization 对长对话、长资料做压缩和摘要,保留关键状态,降低 token 成本。 (OpenAI 开发者) State Management 不只是记聊天记录,而是维护任务当前做到哪一步、还差什么、下一步该干嘛。 (OpenAI 开发者) Working Memory 模型当前这一轮真正能看到并利用的信息集合,相当于临时工作台。 (OpenAI 开发者) Tool Context 工具可不可用、工具返回了什么、执行到哪一步,这些也逐渐被当成上下文的一部分。 Prompt Caching / Prefix Reuse 前面重复的上下文尽量复用,不要每次都从头算,省钱也提速。 KV Cache 模型在长上下文推理时保存中间状态的缓存;上下文越长,它越贵,成了系统瓶颈之一。 (Hugging Face) KV Cache Compression 压缩 KV cache,尽量在不明显掉效果的前提下,把长上下文的推理成本压下去。 (Hugging Face) Trimming 对话太长时,直接裁掉不重要的旧内容,把窗口让给更关键的信息。 (OpenAI 开发者) Context Window 模型一次最多能看到多少 token,也就是它这张临时工作台有多大。 Context Budget 在有限窗口里,给系统规则、历史、记忆、检索资料各分多少 token 配额。
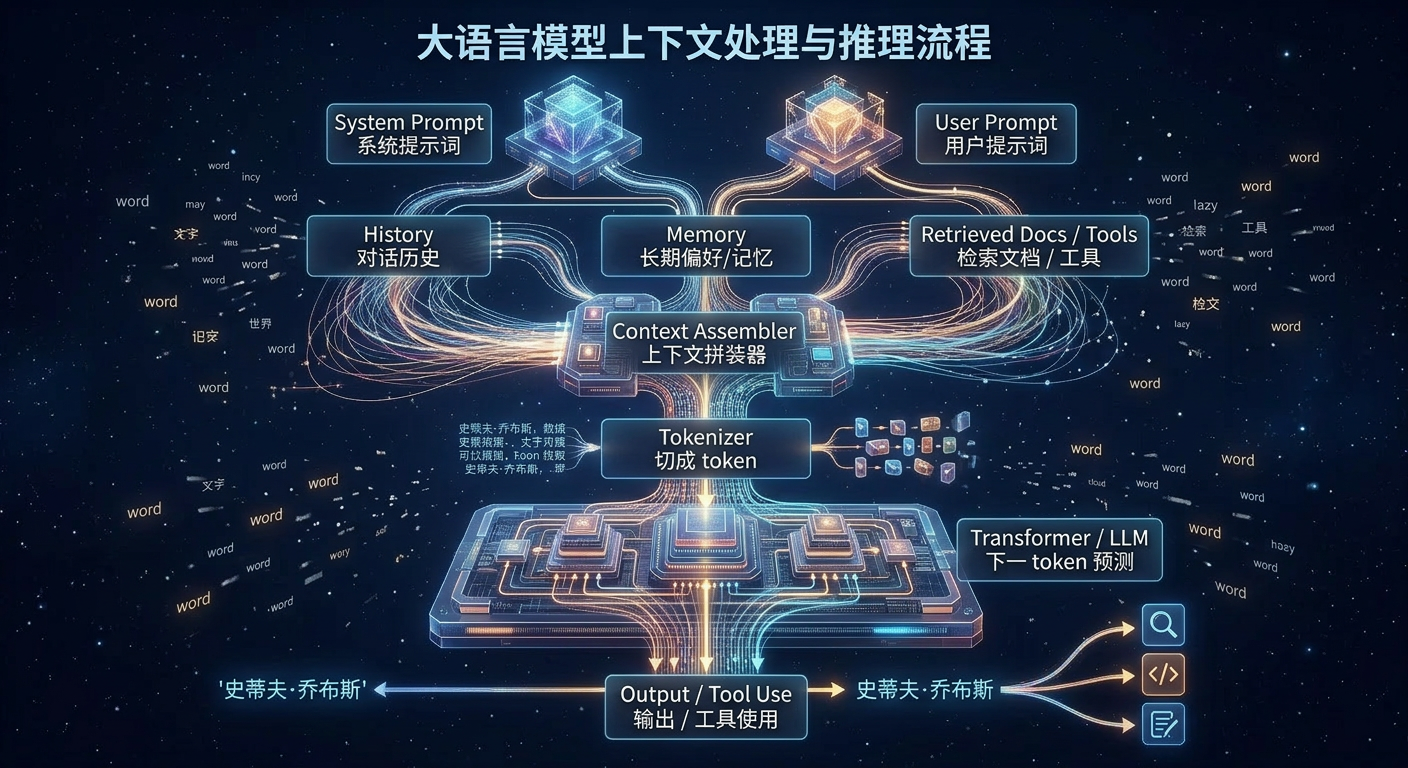
Q7:什么是 Memory?长期记忆
智能体需要长期记住和调用的内容。
Context 是办公桌,Memory 是档案柜。办公桌上的材料,是你这一刻正在处理的东西;档案柜里的材料,不会永远摊在眼前,但需要时可以随时调出来,重新放回桌面。
长期记忆是外部系统负责的,只是智能体会被设定成每次输入需要先去阅读或者加载这部分内容,就像智能体真的记忆住了。
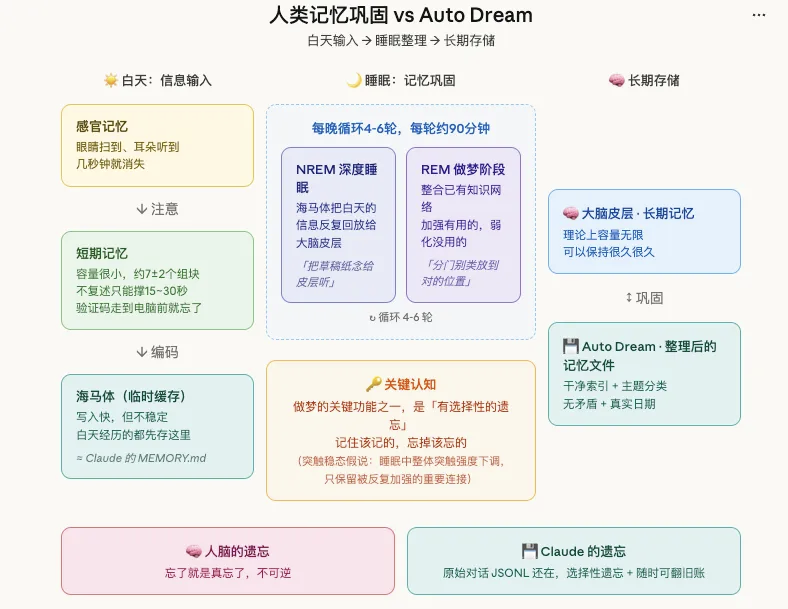
在近期泄漏的 Anthropic Claude Code 内部核心文件里,其名为“做梦(Auto Dream)”和“卡伊洛斯(Kairos)”的后台常驻机制被彻底解密:
当对话闲置时,系统会悄无声息地唤醒一个专属的巡检模型,对你白天的海量交互记录进行反射性重载。
正如其泄露的底层 Prompt 所警告的那样:“You are performing a dream — a reflective pass over your memory files. (你正在做梦——对你的记忆文件进行反射性遍历)”
5.3 硅基智能体如何行动?
过去的大模型更像一个只会聊天的脑子。
你问它问题,它给你答案;它聪明但它只能在语言里活动,不能直接接触现实世界。它知道天气是什么,但它自己不能去查最新天气。它知道代码应该怎么改,但它自己不能真的打开你的文件替你修改。
Q7:什么是 Tool 工具?
为了让大模型接触到现实世界,为了让大模型可以对现实状态做出更改,人类给AI接入了各种可以调用的外部能力接口。
搜索、计算、阅读、发文件……
模型学会了在某些问题分布下,输出“调用工具”这种行为模式,但大模型本身不会输出动作,仍旧是输出文本/json格式的调用,但文本会在「系统」里触发工具调用,获得结果后再通过上下文工程重新输入大模型循环出最终答案。
模型在一次完整推理中判断是否需要工具,如果需要,则由系统执行工具,并将结果回注上下文,再由模型进行下一轮推理,直到得到最终答案。
Q8:什么是 MCP 协议?
MCP,全称 Model Context Protocol,模型上下文协议,让大模型以统一方式接入外部工具、数据源和环境的一套标准协议。
大模型系统如何和工具沟通的统一规则,秦始皇的车同轨书同文,统一度量衡。
由 Anthropic 在 2024 年末正式提出的,2025年,openai和google接入,2025年12月,将MCP协议捐赠给了代理智能体基金会(Agentic AI Foundation, AAIF),Linux 基金会(Linux Foundation)旗下的一个定向基金。
它解决的核心问题是,模型如何以统一的方法发现、理解和调用不同来源的能力,而不是每接一个工具就重新造一套轮子。
如果说 Tool 是单个工具,那么 MCP 更像工具的通用插座。它不直接完成任务,但它规定了能力如何被暴露、上下文如何被传递、调用方式如何被描述、返回结果如何被组织。这样一来,模型面对不同工具时,不需要每次都重新适应底层细节,而可以按统一协议去理解外部能力
Q9:什么是 Agent 智能体?
如果说 Tool 解决的是大模型如何接触和影响现实世界,MCP 解决的是大模型如何以统一方式接入这些外部能力,那么 Agent 解决的问题是
如何把原本只会单轮输出文本的大模型,放进一个可以循环、调用工具、记录状态、持续推进任务的系统里。
Agent(智能体),指的是一种不只是回答问题,而是能够围绕目标自主规划、自主调用工具、根据结果不断调整步骤,直到完成任务的系统。
这是硅基智能和碳基智能一起努力的结果,AI通过训练和学习,学会了像一个执行者一样思考,会倾向于对问题进行拆解,其次是人类给AI搭好了一套框架或者架构来辅助(外部控制系统)其变成agent。
ReAct,全称 Reason + Act,是一种经典的 Agent 工作流范式。
ReAct:Reason + Act
Thought → Action → Observation → Thought → Action → Observation …
Agent = LLM + (Tool + Memory + Workflow)=LLM+Harness
Agent = 会推理的模型 + 会用工具的能力 + 会持续完成目标的控制逻辑
Q10:什么是 Harness 工程?
人们的需求从需要大脑逐渐进化成需要一个生产力工具,在上面的概念里,过去都在努力解决输入侧的问题,但当模型进入真实环境,开始连续行动时,谁来监督它,约束它,纠偏它。
AI的不稳定性,AI被人诟病或者大家日常使用过程中的一个体验是,它会幻觉,它会假装工作,是AI目前还是实验和局部规模的阶段性问题。
- 一上来就想一口气做完整个任务
- 做了一半忘了自己原本要干嘛
- 自己脑补任务已经完成了
- 改了一堆东西却不留记录
- 工具会用,但不会验证结果
- 下一轮回来像失忆一样重新摸索
- 在一条错误路径里不断重试
但AI的不稳定性不是一棒子打死AI的点,这里同样可以用积极心理学来区分,在经历AI假装工作的同时,我们也在经历另外一个事实,即AI有时候能高效奇迹般地完成我们的需求,给我们ahamoment的时刻,所以关键在于不在于AI行不行,而是如何让它可以在一个长链路的线程里稳定重复地行。
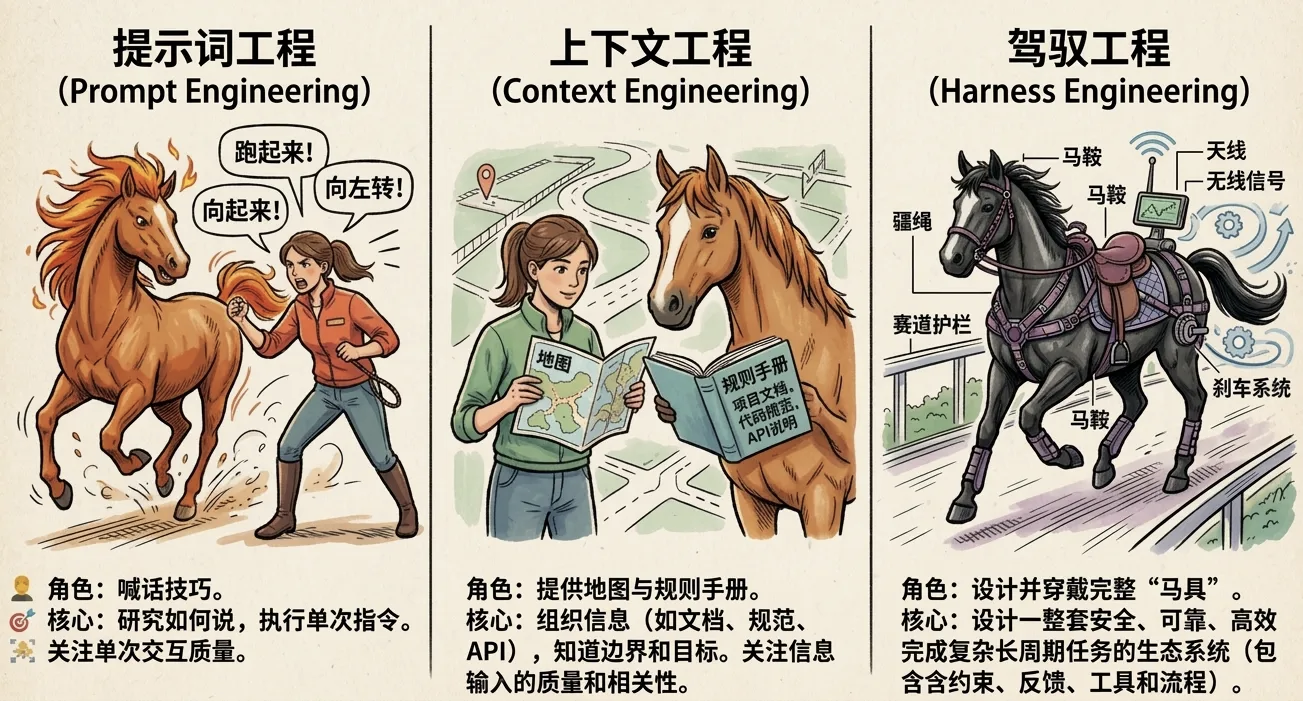
为了教会Agent如何稳定工作(人类大学生毕业)实现这个目标,AI大企业引入了一个新词汇——Harness。(对话智能-长城智能体)
Harness,近期AI圈最火热也是讨论程度最多的词汇,本意是马具的缰绳、嚼子、马鞍等或者一套控制马的工具,本质意思是智能体作为强大的快速的模型,但是不知道往哪里跑,如何稳定快速地跑到符合人类期望的终点。
而Harness工程是一个很大的词汇,Langchain给的定义是智能体=model+harness,即Harness是模型之外的一切,智能体如何稳定工作任何相关工程,任务拆解,上下文管理,工具编排,权限设定,状态交接,验证,恢复,人类接管……
1 大家不用觉得Harness觉得很远,我们给AI设立的边界,我们给AI建立的长期记忆,本质都算是harness工程的一部份
2 其次Harness确实大幅提高了智能体的整体表现
- langchain,不改变模型仅改造Harness,使得排名从30之外冲到了前5
- openai通过仅有几名人类工程师的团队,通过0行手写代码的约束,完成了超百万行代码的生产级应用
- Anthropic,仅凭一句自然语言,无需人工干预,使得智能体交付了一个完整的游戏编辑器和数字音频工作站
3 生成-评价分离
- AI存在和人类一样的自评失真,倾向于高估自己,所以生产和验收需要分离
- Anthropic,角色划分,planner,gennerator,evaluator,dreamer
- 同样的思路,google的Aletheia,2026年2月,面向数学研究的自主agent,generator,verifier,reviser
- Openai早期使用agents文档导致模型输出质量变差,后面长期记忆文档变成目录页索引
- 当代码生成速度超级快,生成代码超级多,验证者不可能再是人类
4 做对的事情,把事情做对
- Openai,不是更努力的尝试,而是缺少什么能力
5 不是新东西,但是面向新对象,不是新瓶装旧酒,也不是只是套壳,过去的harness工程约束的是人生产环境的不确定性,现在的harness工程约束的是智能体在生产环境的不确定性
6 落地:谁该怎么做?
6.1 个体:如何应对?
碳基生物与硅基生物相处指南
写个体。也就是普通人、知识工作者、研究者、创作者,面对 AI 应该怎么用,怎么不被它带歪。这个部分不是教工具,而是教姿势。这里面最核心的不是 哪个模型更强,而是几条原则:不要把思考外包给 AI,不要把它当神谕,要把它当副驾、实习生、执行系统;要有工程思维,也就是把问题拆清楚、把输入设计清楚、把流程管理清楚;要有验收意识,知道 AI 给你的不是答案,而是待验收的中间件;要把 AI 拉进真实任务,而不是只在聊天框里空转;要用它扩带宽,而不是用它掩盖空心。这一小节的关键词其实不是 使用 AI,而是 驾驶 AI。
1 姿势摆正
转变对AI的态度
- 你和世界的关系,你和所有APP的关系,变成了你和自己需求的关系,你和自己的关系,每个人都不得不开始思考或者焦虑,是啊,我要用AI来干嘛呢?
- 这个现象是中性的,但对问题的应对是多义的,有人觉得AI在剥夺自己的思考,有人觉得AI在抢自己的饭碗,有人觉得AI是三体的降临派。——Agent是一等公民
- agent是抢我饭碗的码奸
- agent是我的驾驭的下属
- agent是和一起共事员工
- agent是带我起飞的大佬
主动蒸馏自己
- 接手重复和繁琐的琐碎的任务
- 专注于战略和不可量化的地方
放下AI的执念
- 放下AI不回犯错的执念,类比人,人类也会犯错,人类需要10几年学习,需要法律约束,需要道德束缚
- 放下AI会抢饭碗的执念,使用AI增强你,奖励你
2 主动拥抱
不计成本
- 和增加约束不冲突,约束增加的是创造力
- 在实践过程中主动营造创造一个token不缺的成本
- 除了追求一流大模型,主动harness也是有效路径
工程思维
- 不要把思考外包给 AI,让AI逼迫你或者辅助你思考
- 要把 AI 拉进真实任务,而不是只在聊天框里空转
- 主动分离任务的角色,主动拆解任务
- 对人,多做任务切割
- 对AI,多使用子智能体和多智能体
验收意识
- 生产和验证者分离
- 主动设计验收机制
个体在 AI 时代要有一种看似奢侈、其实必要的心态,叫不计成本地创造试验环境。这里说的不计成本,不是无脑烧钱,而是在关键阶段不要被那点 token 成本吓得抠抠搜搜。约束增加的是创造力,不等于你要在探索阶段把自己锁死在成本焦虑里。
3 找到真金
找到自己的创造力
1 找到让你浑身难受的东西
1.1 认知失调:预期与现实出现了误差,改变自己还是改变世界
1.2 多点琢磨,不要将就
2 主动给自己加约束(less is more )
2.1 AI领域加约束会提高表现
加拿大 UBC(英属哥伦比亚大学)的李霄霄(Xiaoxiao Li)教授团队于 2026年1月 发表的,论文题目叫:《When Single-Agent with Skills Replace Multi-Agent Systems and When They Fail》
2.2 人类也需要给自己加约束
选择越多,行动越低
约束工具,约束时间,约束范围
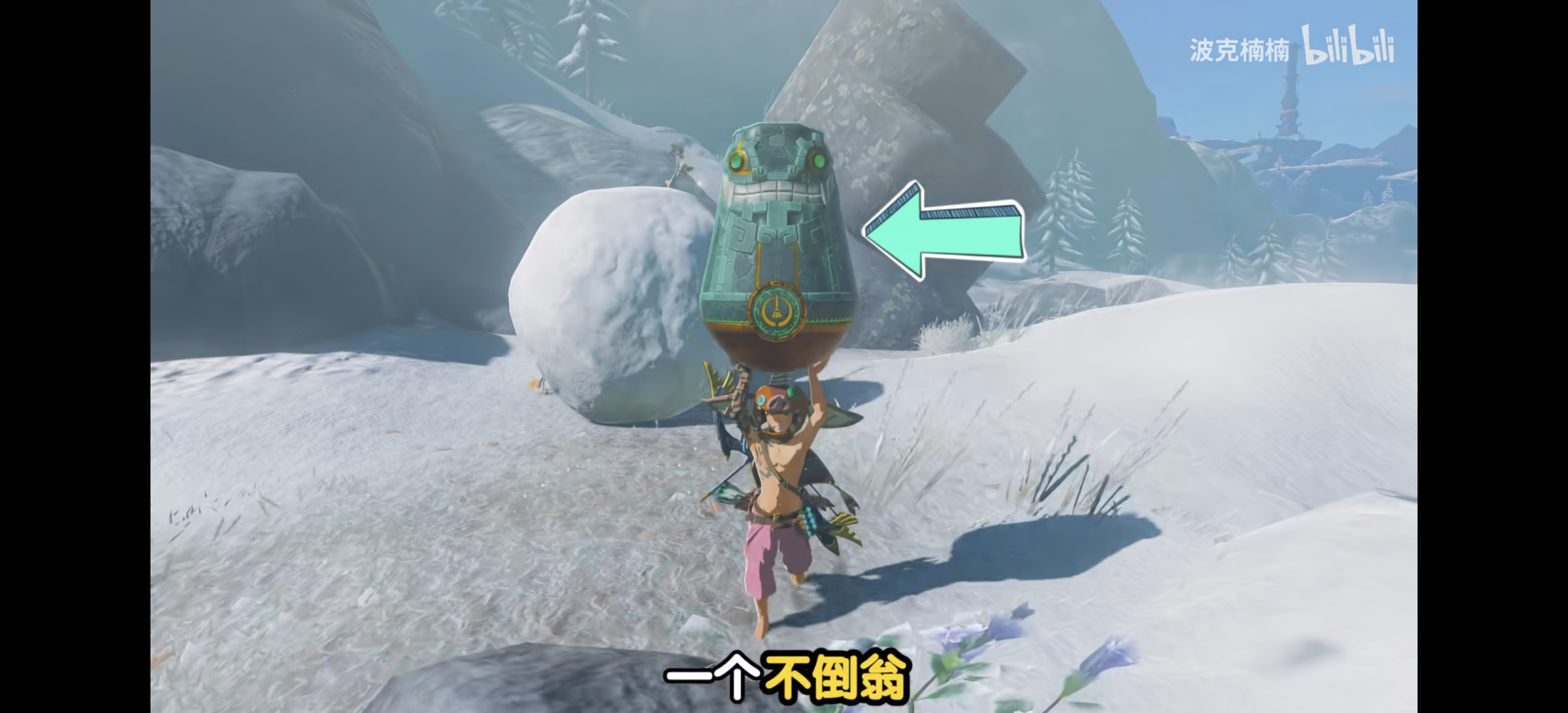
2.3 塞尔达传说:AI如同这个不倒翁
3 先完成后完美
先让AI入驻进来(种下一颗种子)
4 跨界
创造力的起点,反而不是灵感,而是不舒服。真正能把 AI 用明白的人,往往不是最会玩提示词的人,而是最先意识到哪里不对劲的人。是哪些重复劳动让你烦,是哪些低效流程让你卡,是哪些预期和现实之间的误差让你浑身难受。
找到无法被蒸馏/难以被蒸馏的部份
这一部分仍然是个体在 AI 时代需要主动识别和保留的真金。真正稀缺的,不是更快地产出平均答案,而是那些很难被外包、很难被压缩、很难被复制的人类部分。
反脆弱
与不确定性做朋友,不要只想着别被它打死,AI带来的是混乱,是黑天鹅,是动荡与不确定性。
1 很多人面对不确定性,天然反应是回避、控制、消灭、求稳,不想要被其杀死,这其实只是防守人格。
2 把不确定性看作中性的现实,既然这个世界本来就由不确定性主宰,那为什么不想办法从中捞一笔。
3 别把自己活成白天鹅统计员,要把自己活成黑天鹅受益者。你不用比别人更会预测,你只需要比别人更不怕世界变脸,实事求是,做好应对。
4 脆弱的反义词不是坚固,而是一种在随机过程中会变得更好的东西
5 玻璃杯摔一下就碎,是脆弱;不锈钢杯摔一下不碎,是坚固;但还有第三种东西,是越在随机冲击中越强,这才是反脆弱。
4 其他
现状,中间层要被拷打
- 利好大企业,管理经验/用户/渠道/品牌/合规
- 利好小企业,重构,船小
门槛消融带来的行业转变
- 技能型的学习转变-skil
- 知识储备型职业的转变-沉淀
- 心理咨询师
- 孩子教育,依赖AI导致思考退化-孩子教育,驾驭AI导致无所不能
ADHD,反而成了 AI 时代的版本答案?!
AI 时代带来的那种沉浸式多巴胺快感,正在让我们 ADHD 成为版本最强。
AI 时代信息密度和工作节奏变化极快,能在混乱中持续保持判断力和创造力,这项能力正在变成「AI 时代稀缺的竞争力」。
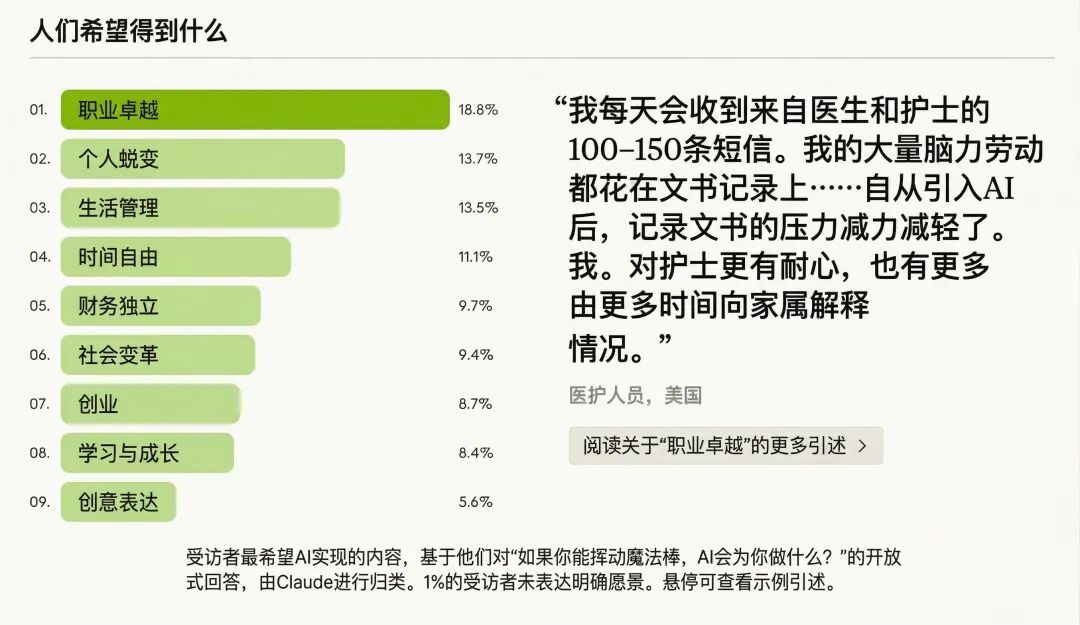
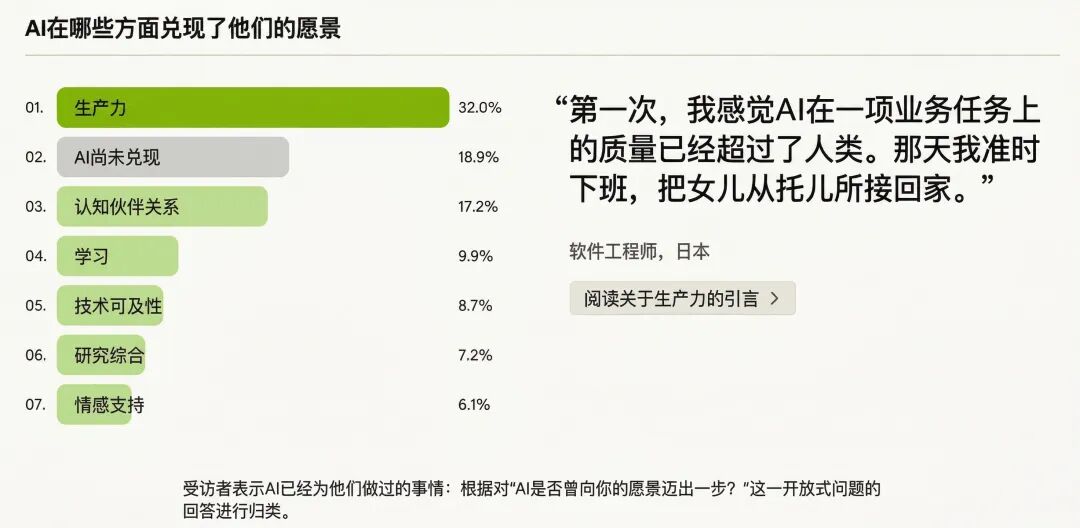
Anthropic 最新报告:8 万普通人对 AI 的恐惧和期待
Anthropic 最新报告:8 万普通人对 AI 的恐惧和期待
用 AI 辅助学习,却发现自己开始懒得独立思考了;
赞叹 AI 的判断力,又在关键时刻被它一本正经的胡说八道坑过;
从 AI 那里获得深夜的慰藉,转头发现自己已经很久没找真人聊过了;
用 AI 在某些事上省了时间,结果老板的期望值跟着涨了;
靠 AI 开辟了副业收入,同时也在担心 AI 会不会让自己的主业消失。
不同岗位的游戏人,都是怎么用 AI 的?
我会告诉自己真正要写的东西,得在AI给我的内容的标准之上,也就是给自己强制上思想钢印,不把AI当笔或者是代写,而是变成文案赛马的对手,你得写出来它写不出来的东西。
我自己在家的时候则是秉承“能自动化就自动化”的原则做了不少有趣的小工具。比起单纯地用AI完成工作,我更想让AI把自己的工作环境、工作节奏调整得更顺滑。
7 观点
前面讲了感受、背景、学习和落地,到这里可以把一些更明确的判断收束成几条观点。这些观点不一定都是终局答案,但至少可以作为未来几年观察 AI 的坐标系。
7.1 从对话式 AI 到行动式代理,人类会逐渐退到“头”和“尾”
过去很多人理解 AI,还是停留在“它会聊天”“它会回答问题”“它会写点东西”。但真正的变化,不是对话式 AI 更会说了,而是行动式代理开始进入真实工作流了。它不再只停在聊天框里给你建议,而是能接任务、调工具、读上下文、执行步骤、产出结果,甚至在一定边界内自己迭代。
这会让人类在很多任务里逐渐退到两个位置:头和尾。头,是做对的事情,定义目标,决定什么值得做,什么不值得做,先打哪一仗,为什么打这仗;尾,是验收成果,判断做出来的东西到底对不对、好不好、能不能承担后果。中间那一大段 HOW,以后会越来越多地由 AI 代劳。
所以未来一个人真正的稀缺能力,未必只是知道更多知识,而是有更强的想象力、更清楚的目标感,以及更成熟的验收标准。知识当然重要,但知识正在变成越来越容易被调取的库存;而想象力、问题定义、责任承担和 taste,反而在升值。软件也会顺着这个方向演化,从“软件即服务”逐渐走向“结果即服务”,用户购买的不再只是一个界面,而是一个可交付的结果。
7.2 能力越强的系统,越需要精密的外部控制
大模型不是一个传统意义上的确定性函数。你不能指望像调用数学公式那样,输入完全相同的东西,每次都得到完全一致、完全可靠的结果。越是能力强的系统,越像一个高智商但不稳定、能干却也可能跑偏的实习生。它有创造力,也就有偏航风险;它有泛化能力,也就有幻觉和误判。
这意味着工程重点会从“怎么把话说清楚”进一步转向“怎么把模型放进一个能够持续稳定地产出结果的框架里”。Prompt engineering 只是起点,后面更重要的是 context engineering,是 harness,是工具权限,是上下文裁剪,是错误恢复,是多步执行时的状态管理,是人和系统之间的责任分界线。
越强的系统越不能裸奔。真正的竞争力,不只是你接了哪个模型 API,而是你有没有把这个模型包进一层足够好的外围控制系统里,让它在真实世界里既能干活,又不至于惹祸。
7.3 AI 时代的人类价值,会越来越集中到“验收”
如果中间执行过程越来越多地交给 AI,那么“尾”就会变得极其重要。所谓尾,本质上就是验收意识。不是看它做没做,而是看它有没有做对;不是看它给了你一个看起来像答案的东西,而是看这个东西在真实环境里能不能承担责任。
工程思维在这里会比灵感更重要。很多时候,你不需要神乎其神地驯化 AI,你只需要手动多设计一个验收任务,就能让系统稳很多。比如让一个代理生成结果,让另一个代理审查结果;比如输出后自动跑一遍 build、测试、lint;比如在关键节点要求人工确认;比如多一个 GitHub 备份动作,多一个人工兜底动作。很多事故不是因为 AI 太弱,而是因为人类太急,省略了尾部验收。
以后谁最懂验收,谁就更容易驾驭 AI。因为策略制定决定方向,验收能力决定结果,而中间执行正在被快速商品化。
7.4 当 HOW 逐渐由代理完成,GUI 不再是唯一中心
过去几十年的软件世界,基本是围绕 GUI 构建的。因为执行对象是人,人需要看见按钮、表单、导航、菜单,需要一条清晰固定的用户路径。可一旦越来越多的执行对象从人变成 AI,很多为人类设计的软件结构,就会慢慢从“默认答案”变成“历史阶段答案”。
这不意味着 GUI 会消失,而是它不再天然占据中心。更底层、更关键的东西会变成模型原生范式、上下文组织方式、工具调用协议、权限系统和代理到界面的桥梁。MCP 这类协议的重要性会越来越高,因为它们解决的是“代理如何安全稳定地接入世界”的问题。某种意义上,未来的软件不只是给人用,还要给代理用。
CLI 这件事重新变热,也和这个趋势有关。CLI 本质上就是用结构化文本表达意图,并让计算机按规则执行。它天然适合人与机器、机器与机器之间的协作,所以在 AI 时代反而重新显示出生命力。
7.5 AI Agent 爆发,本质上是一场新的基础设施红利
如果把 AI Agent 想成一批突然降临地球的“外星劳动人口”,很多问题会变得非常好理解。它们不是天然就能在地球环境里干活,它们需要装备,需要食物,需要住所,需要交通,需要规则,需要培训。谁能给这批新劳动力提供基础设施,谁就有机会吃到未来十年的红利。
衣,是 harness,是包在模型外面的程序壳、调度层、权限层、输入输出层、错误处理层。食,是算力和数据,是 token、数据主权、知识沉淀、技能 SOP、上下文压缩与持久记忆。住,是物理设备、服务器、边缘节点、人机协作网络。行,是 API、MCP 以及各种让代理能安全连接外部世界的标准接口。
所以未来的巨大机会,不只是“做一个 AI 应用”,而是做一整套让代理能安全、高效、持续劳动的配套系统。
7.6 今天的 AI,很像互联网和移动互联网的早期阶段
今天的 AI 有点像互联网和移动互联网刚开始真正进入大众生活时的状态。大家都知道它厉害,也都能模糊感觉它会改世界,但真正稳定、便宜、标准化、人人离不开的形态,还没长出来。很多体验像早期上网,能力很惊艳,但基础设施不成熟,成本高,波动大,产品形态也还在频繁试错。
早年的智能手机时代,很多人每个月只有一点点流量,看网页还要手动设置“不加载图片”,整个产品世界都围着稀缺资源打转。今天的 token 成本、上下文限制、稳定性问题,有点像那个阶段。未来智能很可能会逐渐向电价一样的基础成本收束,变成像互联网服务一样的底层公用能力,但这中间还要经过一大轮基础设施建设,包括稳定性、边际成本、权限体系、审计能力、数据接入标准和用户习惯沉淀。
真正的变化,不是给旧软件前端塞一个聊天框,而是重构整个软件的交互逻辑、任务流、权限流和组织分工。软件会从“给人用的工具”,变成“人和代理一起完成任务的操作环境”。
7.7 AI 正在变成新的环境,而不只是一个新工具
很多人现在还在问:“你会不会用 AI?”这个问题有点像当年问“你会上网吗?”再往后,它甚至会像问“你会不会用电”一样,逐渐失去提问意义。AI 会慢慢从一个显眼的新工具,变成一种新的底层环境。
1945 年第一颗原子弹爆炸后,连远处丛林都能检测到放射性痕迹。某种意义上,2022 年 ChatGPT 出现之后,AI 味也开始进入自然语言环境。我们现在越来越容易怀疑一段话是不是 AI 写的、一个视频是不是 AI 做的、一个互动是不是 AI 扮演的。它正在从局部产品能力,变成一种弥散在整个社会里的背景辐射。
所以最后的判断其实很朴素:不要神化 AI,也不要轻视 AI。它会犯错,会幻觉,会失控,需要像对待新人一样被训练、被约束、被审计;但与此同时,它正在成为新的基础设施、新的劳动人口和新的社会环境。真正重要的,不是争论它到底是不是万能,而是尽快在这场变化里找到自己的位置,建立自己的判断,开始自己的实践。